
I use mix models as a way to find general patterns integrating different levels of information (i.e. the random effects). Sometimes you only want to focus on the general effects, but others the variation among levels is also of interest. If this is the case, using a random slope model is pretty cool, but making sense of lmer output is not trivial. I provide here code to get the random slopes and CI’s of such models using the iris dataset in R (mainly, because I am sure I will need to check this entry in the future myself)
#This shows how to get the random slopes and CI's for each level in a hierarchical model
Is there a general relationship between petal and sepal width? and how it differs by species?
plot(iris$Sepal.Width ~ iris$Petal.Width, col = iris$Species, las =1


#Our model with random slope and intercept
library(lmer)
m2 <- lmer(data = iris, Sepal.Width ~ Petal.Width + (1 + Petal.Width|Species))
#extract fixed effects
a=fixef(m2)
#extract random effects
b=ranef(m2, condVar=TRUE)
# Extract the variances of the random effects
qq <- attr(b[[1]], "postVar")
e=(sqrt(qq))
e=e[2,2,] #here we want to access the Petal.Weigth, which is stored in column 2 in b[[1]], that's why I use the [,2,2]
#calculate CI's
liminf=(b[[1]][2]+a[2])-(e*2)
mean_=(b[[1]][2]+a[2])
limsup=(b[[1]][2]+a[2])+(e*2)
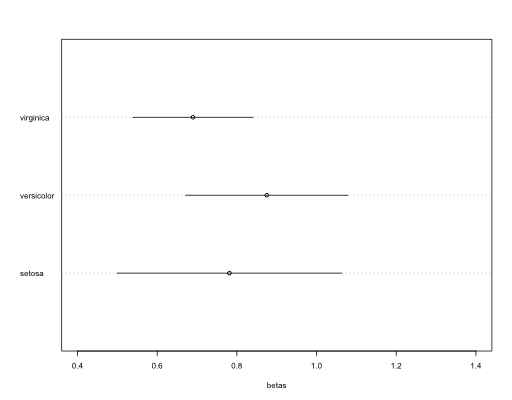
#Plot betas and its errors
dotchart(mean_$Petal.Width, labels = rownames(mean_), cex = 0.5, xlim = c(0.4,1.4), xlab = "betas")
#add CI's...
for (i in 1:nrow(mean_)){
lines(x = c(liminf[i,1], limsup[i,1]), y = c(i,i))
}

#make final plot
plot(iris$Sepal.Width ~ iris$Petal.Width, col = iris$Species, las = 1)
#and plot each random slope
abline(a = b[[1]][1,1]+a[1], b= mean_$Petal.Width[1], col = "black")
abline(a = b[[1]][2,1]+a[1], b= mean_$Petal.Width[2], col = "red")
abline(a = b[[1]][3,1]+a[1], b= mean_$Petal.Width[3], col = "green")
#and general response
abline(a, lty = 2)


The code is fast and dirty, I know I can be more consistent, and the plot can be nicer (clip the slopes, add SE’s), but will work to get the idea.
& thanks to Lucas Garibaldi for sharing much of this knowledge with me.
And the gist: https://gist.github.com/ibartomeus/f493bf142073c704391b
