As researchers, we are supposed to be good at a plethora of things. Managing people is one of those things that nobody teaches us, but that ends up being pivotal for the lab functioning. In fact, I would say that researchers, in general, don’t feel comfortable being a boss and see the time invested in managing people as a burden that prevents them to do more important things such as actual research. I’ve been there, and I think that it is pivotal that (we like it or not, we are good at it or not) we assume part of our job as IP is to be a boss, and we try to be a good one.
With this in mind, I have read several pieces on scrum and agile culture and tried to understand how to create an efficient and happy team. The last book I read was Radical Candor, by Kim Scott. It is focused on managing people at big companies, but I think a lot of stuff can be applied to academics. The main message of the book is that you need to create a culture of caring for people (and for the science you are doing) and of giving clear and honest feedback.
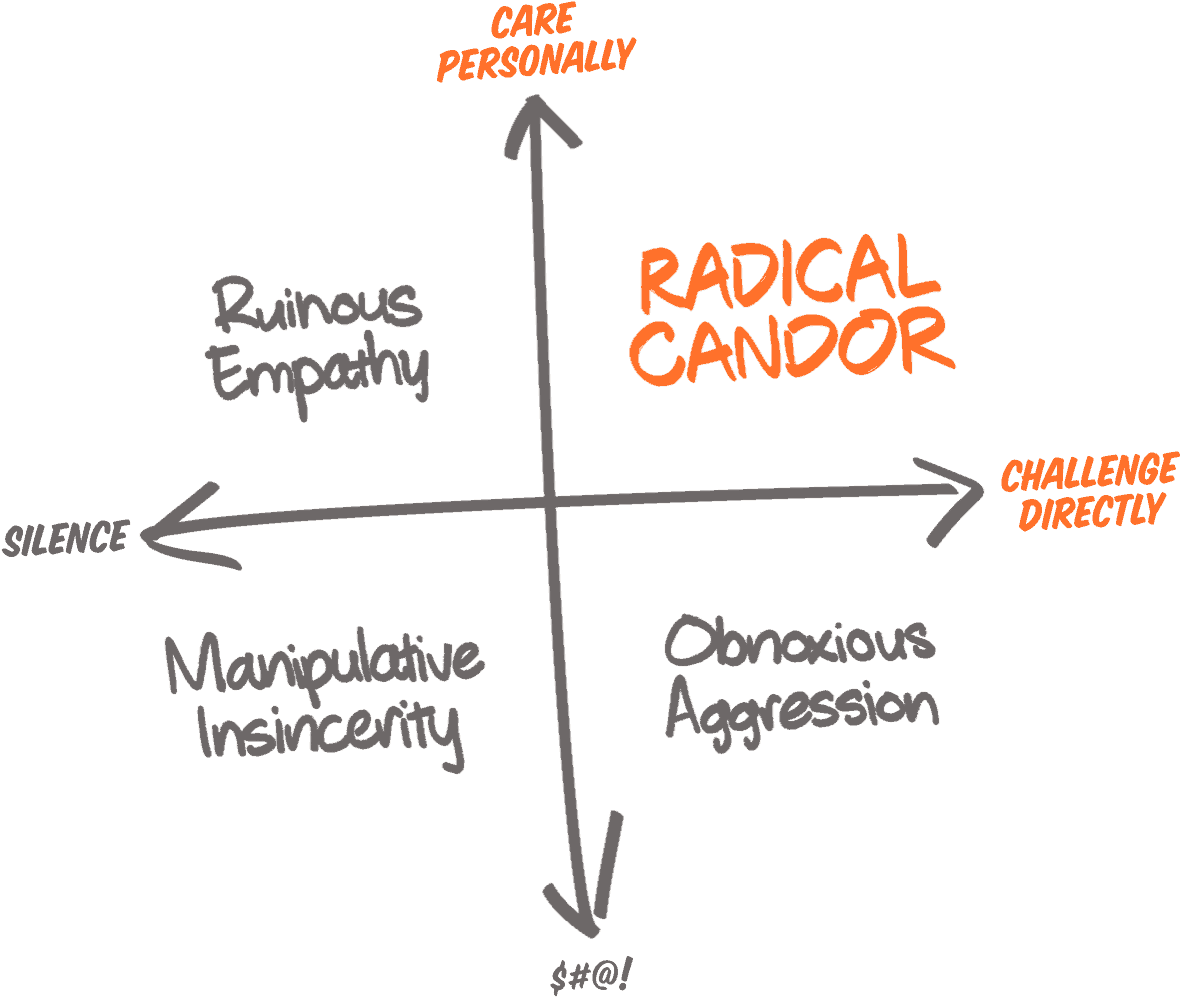
I think that in academia (in general) we are good at caring personally (small labs, with people passionate for science and mind alike, makes it easier), but we don’t always challenge directly. In my own experience, when things go well, it’s super easy for me to give honest feedback and improve the project even more, but when someone is under-performing I have a hard time making that clear, and this is bad for you, for him/her and for the team.
The following are basically notes for me and the lab, with no ambition to be comprehensive or detailed:
The book makes crystal clear that spending a morning listening to your team complain about personal stuff, or about an internal fight or celebrating their success is an integral part of your job. Not a distraction. Your job. This makes it easier to allocate time to that in your daily schedule.
It also encourages focusing not only on people writing the important papers, but on hard workers that make this possible. Having a “stable” lab technician who solves the day to day field and lab work is the best decision I toke as PI so far. Invest in core people. This is really hard in academia where positions depend on short term projects.
Do not personalize. People are not sloppy, they may have done a particular job in a sloppy way. Then, Its easier to fix specific actions. The “Situation-behaviour-impact” chain is the best to describe a problem. The best feedback is given often and in impromptu situations, is specific about the problem and offers solutions.
If you want feedback (or criticism as stated in the book) to be part of your team, cultivate it at all levels. Encourage criticism also towards yourself (or your ideas) and among your peers. I like the following process to encourage criticisms, starting by listening (not by replying to criticism or cutting it or offering excuses). When you got criticism, ask to give details and strive to understand it. Do not react. (I’ll apply this also to my normal life).
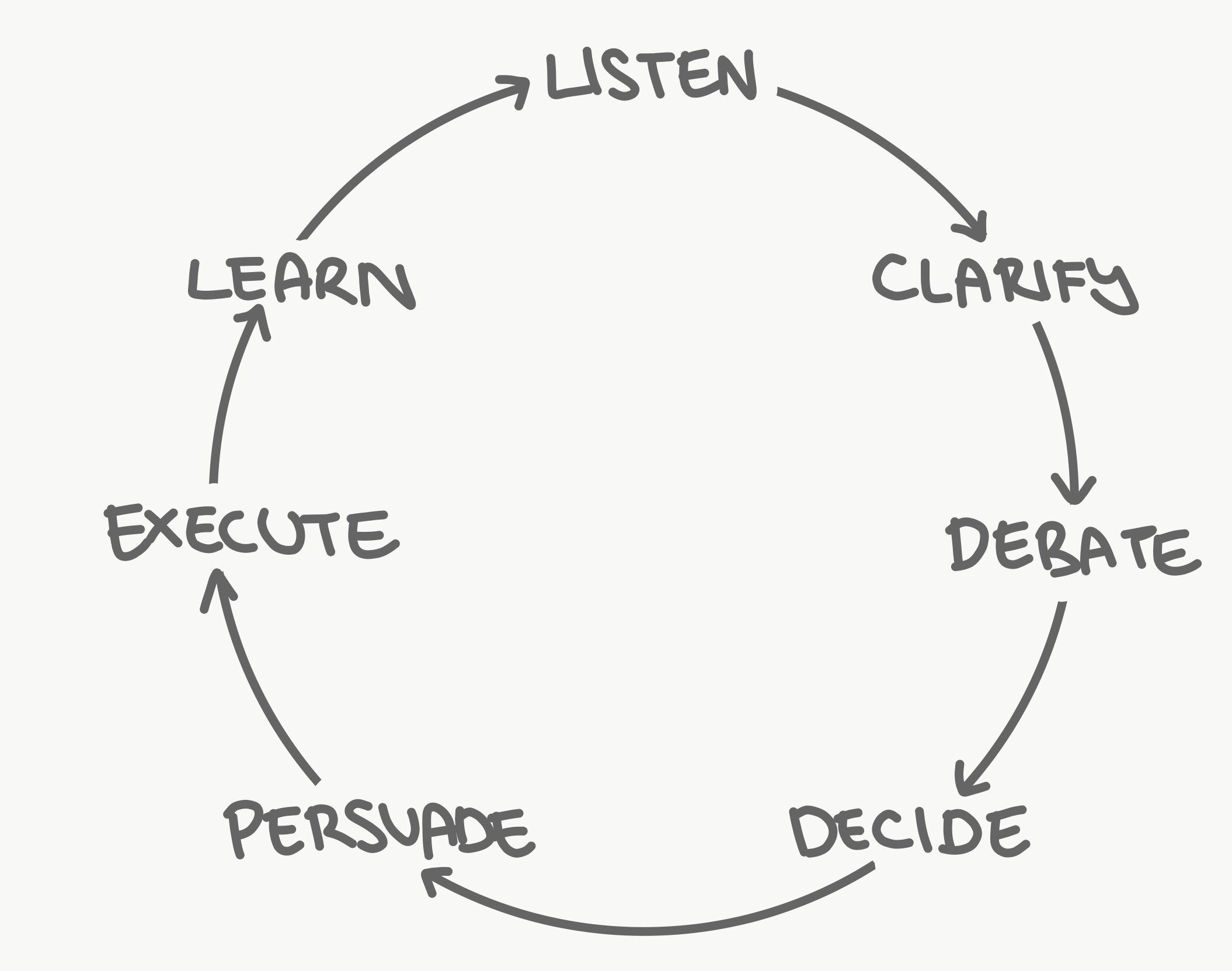
I was reinforced on running retrospectives after papers are published in the lab. The book also recommends blocking time for thinking and for working on personal projects, something I am also doing (albeit I should do more) so I don’t spend the day in meetings.
Finally, It made me think about the lab culture. It’s hard to judge internally, but I would like to think the lab culture is to be open and replicable (even if we often do not achieve it!), to put people first and to be risky in our ideas and approaches (even if this means we often go for the big picture, and miss some of the important details). We also are committed to outreach.




























 Drawdown is the point when the current CO2 worldwide concentration starts to decrease. It’s a book highlighting 100 solutions already available to reverse climate change and a few more solutions to come. Its a positive and optimistic book and it’s what I needed to read after a few months feeling quite pessimistic about the actual situation.
Drawdown is the point when the current CO2 worldwide concentration starts to decrease. It’s a book highlighting 100 solutions already available to reverse climate change and a few more solutions to come. Its a positive and optimistic book and it’s what I needed to read after a few months feeling quite pessimistic about the actual situation.

